Proyek Akhir
SalarySense — Big Data Project
Dokumentasi proyek prediksi gaji berbasis Machine Learning dan deployment Streamlit.
SalarySense: Prediksi Gaji Menggunakan Machine Learning dan Streamlit
SalarySense merupakan proyek akhir Praktikum Big Data yang bertujuan untuk membangun sistem prediksi gaji tahunan berbasis Machine Learning.
Aplikasi ini membantu pengguna memahami estimasi gaji, posisi gaji di pasar kerja, serta proyeksi pertumbuhan gaji di masa depan berdasarkan profil pekerja.
🔗 Link Aplikasi Streamlit:
SalarySense Streamlit App
🔗 Link Repository GitHub:
GitHub Repository
1. Deskripsi Dataset
Dataset yang digunakan berisi informasi profil pekerja dan gaji tahunan. Dataset ini digunakan untuk melatih model Machine Learning dalam memprediksi gaji berdasarkan beberapa faktor penting.
- Age (Usia)
- Years of Experience (Pengalaman Kerja)
- Education Level (Tingkat Pendidikan)
- Job Title (Jenis Pekerjaan)
- Gender (Jenis Kelamin)
- Salary (Target / Gaji Tahunan)
Contoh dataset:
2. Exploratory Data Analysis (EDA)
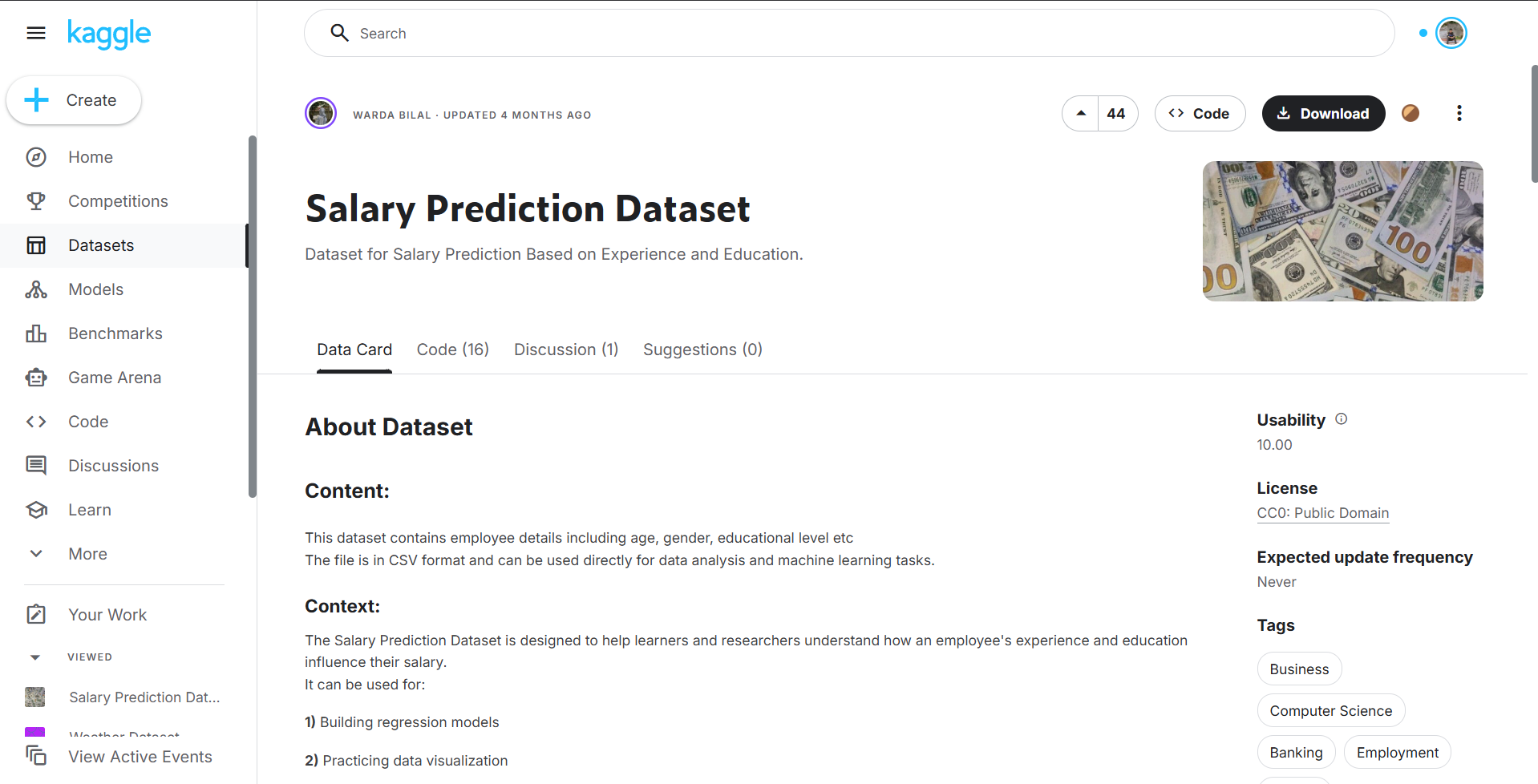
Tahap EDA dilakukan untuk memahami pola data, distribusi gaji, serta hubungan antara fitur dan target.
Distribusi gaji:
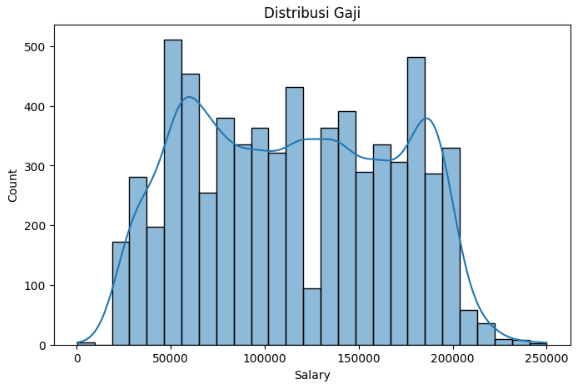
Hubungan pengalaman kerja dengan gaji:
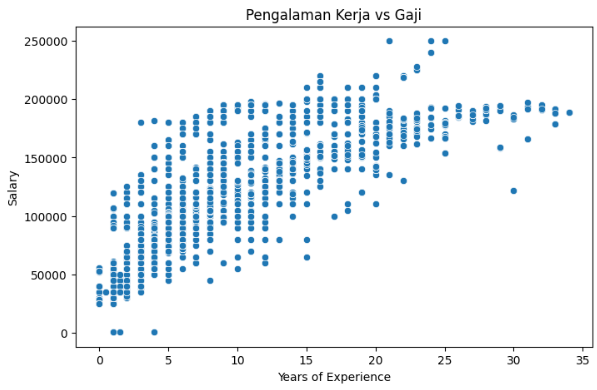
Distribusi gaji berdasarkan tingkat pendidikan:
3. Data Preprocessing
Sebelum dilakukan pemodelan, data melalui tahap preprocessing agar siap digunakan oleh algoritma Machine Learning.
- Penanganan missing value menggunakan SimpleImputer
- Encoding fitur kategorikal menggunakan OneHotEncoder
- Scaling fitur numerik menggunakan StandardScaler
- Penggabungan preprocessing dan model menggunakan Pipeline
Code preprocessing pipeline:
from sklearn.pipeline import Pipeline
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import StandardScaler, OneHotEncoder
from sklearn.compose import ColumnTransformer
# Define preprocessing steps
numeric_features = ['age', 'years_experience']
categorical_features = ['education_level', 'job_title', 'gender']
numeric_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='median')),
('scaler', StandardScaler())
])
categorical_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='constant', fill_value='missing')),
('onehot', OneHotEncoder(handle_unknown='ignore'))
])
preprocessor = ColumnTransformer(
transformers=[
('num', numeric_transformer, numeric_features),
('cat', categorical_transformer, categorical_features)
]
)4. Pemodelan Machine Learning
Dua algoritma Machine Learning digunakan untuk membandingkan performa model.
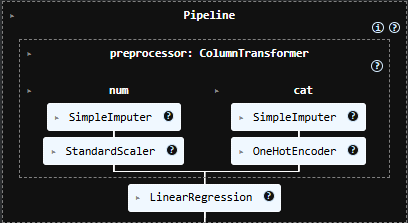
- Linear Regression sebagai baseline model
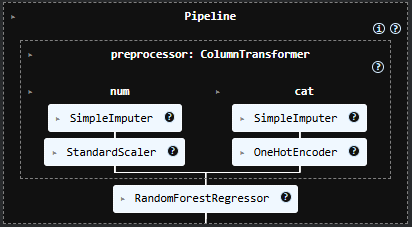
- Random Forest Regressor untuk hubungan non-linear
Model Random Forest kemudian ditingkatkan menggunakan Hyperparameter Tuning dengan GridSearchCV.
Diagram alur pemodelan:
5. Evaluasi Model
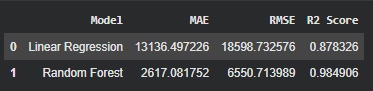
Evaluasi model dilakukan menggunakan beberapa metrik regresi untuk memastikan performa prediksi yang baik.
- MAE (Mean Absolute Error)
- RMSE (Root Mean Squared Error)
- R² Score
Tabel perbandingan model:
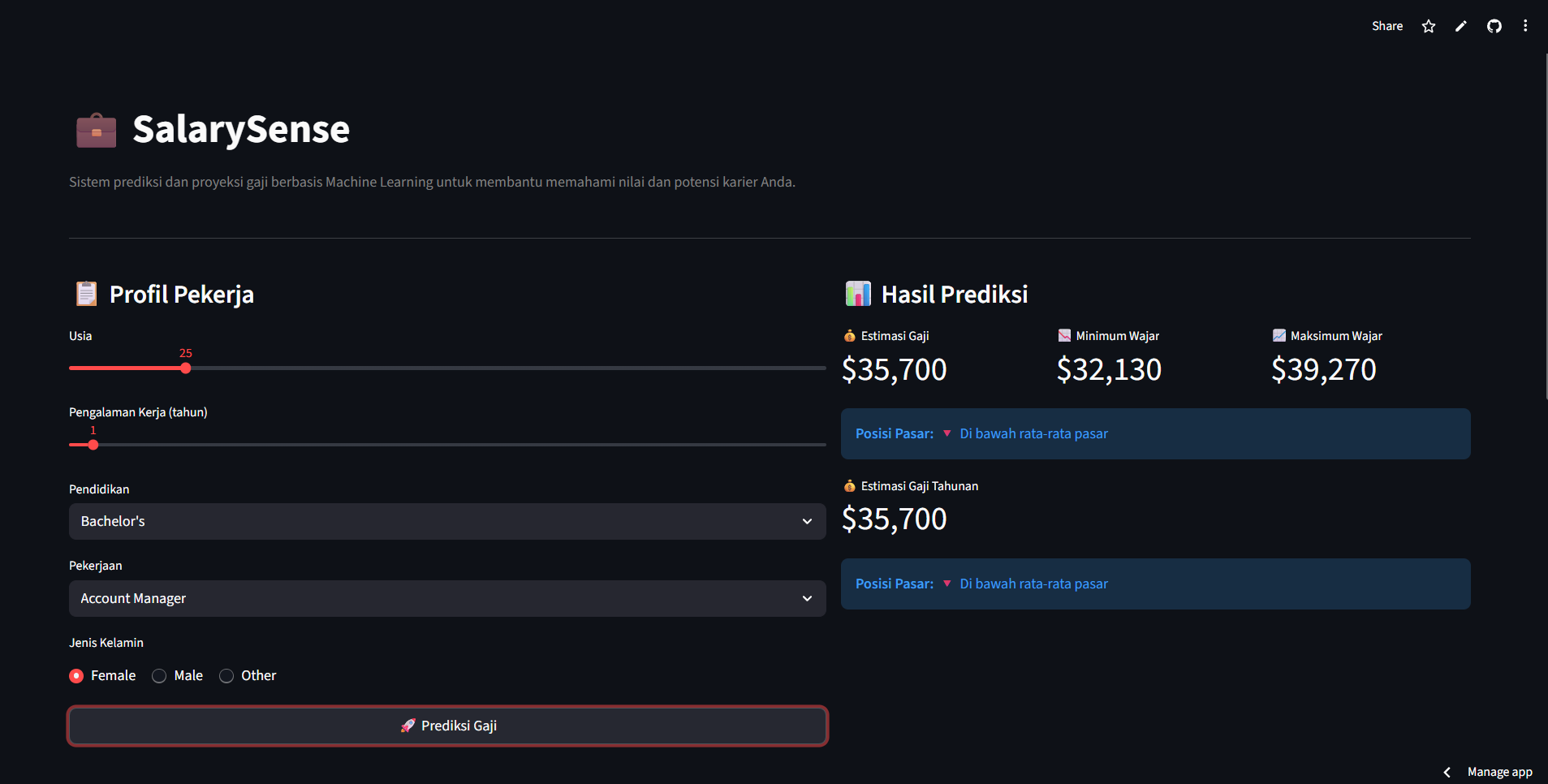
6. Deployment Aplikasi Streamlit
Model terbaik di-deploy ke dalam aplikasi web interaktif menggunakan Streamlit.
Aplikasi ini memungkinkan pengguna untuk:
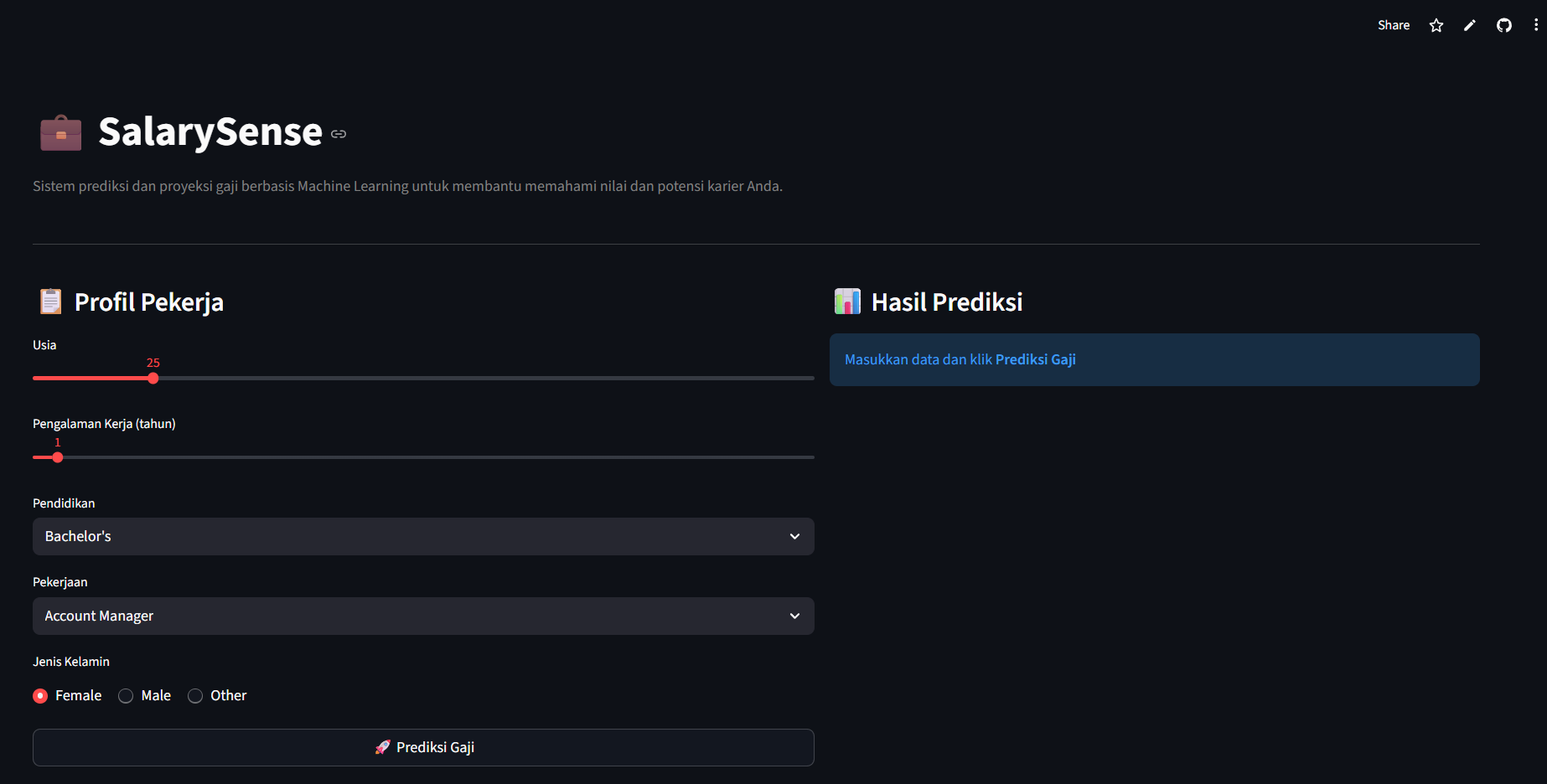
- Memasukkan profil pekerja
- Melihat estimasi gaji tahunan
- Mengetahui posisi gaji di pasar kerja
- Melihat rentang gaji minimum dan maksimum
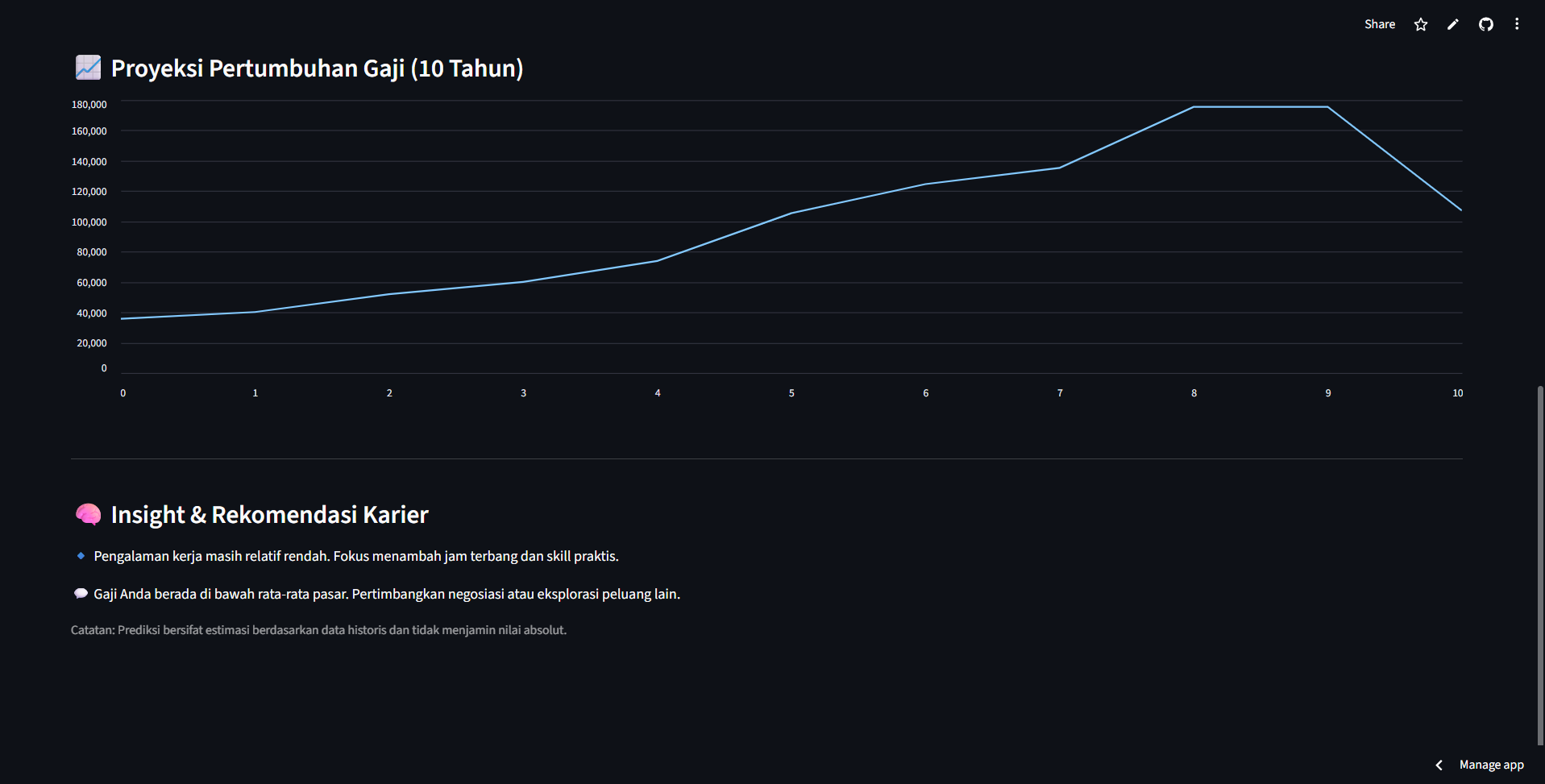
- Melihat proyeksi gaji hingga 10 tahun ke depan
Tampilan input aplikasi:
Tampilan hasil prediksi:
7. Kesimpulan
Proyek SalarySense berhasil membangun sistem prediksi gaji berbasis Machine Learning secara end-to-end, mulai dari pengolahan data, pemodelan, evaluasi, hingga deployment aplikasi web.
Model Random Forest menunjukkan performa terbaik dan aplikasi Streamlit memberikan pengalaman pengguna yang interaktif dan informatif.